
Excelで複数条件の集計をするときに便利なのが SUMIFS関数 です。ここでは、SUMIFS の式の作り方そのものではなく、どのようにデータ範囲を参照するかに焦点を当ててまとめた。
SUMIFS(合計対象範囲, 条件範囲1, 条件1, [条件範囲2, 条件2], …)便利な関数式だけど、式を行方向・列方向にコピーして使う場合にどう書くのが良いか? と悩むことがある。
一度きりの集計なら、列全体を参照する方法が楽。しかし、いくつかのデメリットあり。
=SUMIFS($E:$E, $A:$A, $G2, $B:$B, I$1, $C:$C, $H2)データが増えたり入れ替わったりする可能性がある場合はどうでしょう?また、作った式を 自分だけで使うのか、他の人も見るのか? によっても「最適な書き方」は変わる。
サンプル
以降のいくつかの例で使う表です。
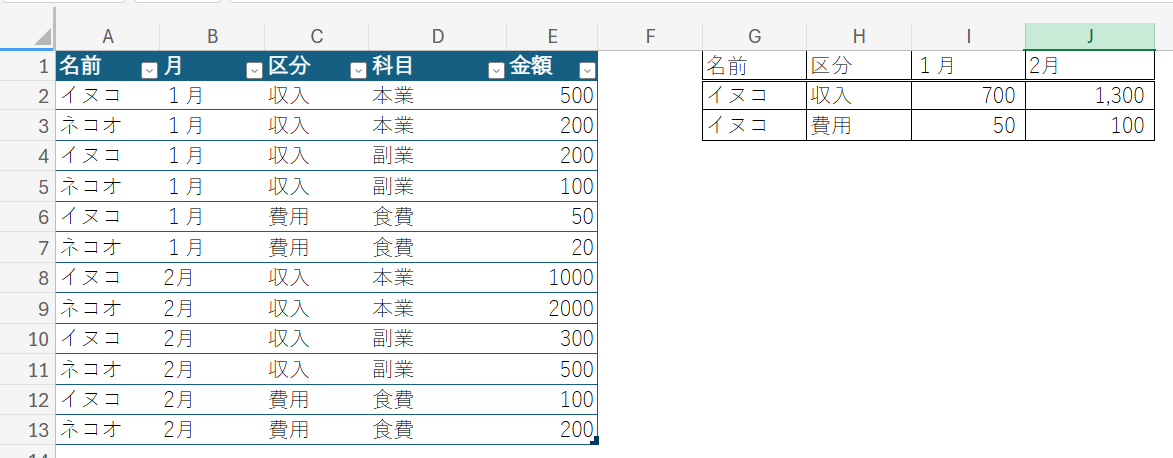
- 式の設定:セルI2
- 列方向と行方向に式をコピーする
データが多いとわかりにくくなるので、シンプルにしています。
基本の式
=SUMIFS($E2:$E13, $A2:$A13, $G2, $B2:$B13, I$1, $C2:$C13, $H2)必要な範囲だけを参照するので軽い反面、データが増えたり減ったりすると範囲を修正しなければならないのがデメリットです。
列全体参照
一番楽な書き方は、列全体を参照する方法でしょう。
=SUMIFS($E:$E, $A:$A, $G2, $B:$B, I$1, $C:$C, $H2)見た目は簡単で、範囲をいちいち指定し直さなくても使えますが、私は何度も使う場合はこの方法は選びません。
良い点・シンプルに見える理由
- どこまでの範囲を集計するかを気にしなくてよい
- 式自体が短く書ける
- データ追加時に範囲を修正する必要がない
注意点・「シンプル」と言い切れない理由
- 列全体を参照するので、裏では Excel が 約100万行分 を計算対象にしている
- データ量が増えると動作が重くなる
- 空白や余計な値を拾ってしまう場合がある
テーブルの構造化参照
例では、テーブル名を「kakeibo」にしている。
Excelのテーブル機能を使った書き方です。
=SUMIFS(kakeibo[金額], kakeibo[名前], $G2,kakeibo[月],I$1,kakeibo[区分],$H2)テーブルにしておくと、列名をそのまま参照できるので式が分かりやすいです。ただし、列方向や行方向に式をコピーする場合、手修正が必要になることがあります。これは、テーブル参照の仕様上、コピー先で参照列がずれる場合があるためです。
テーブル参照のメリット
- データが増えても自動で追従
テーブルに追加された行も自動で集計対象になるので、範囲を修正する必要がない - 管理が直感的
列名で参照できるため、名前定義や OFFSET/INDIRECT を使うより理解しやすい
SUMIFS でテーブル参照のデメリット
- 列方向にコピーすると参照がずれる
- 式がやや長くなる
列名を明示する分、列全体参照より式が少し長くなる - テーブル機能を理解していない人には分かりにくい
- テーブル列を変更すると名前定義も見直す必要がある場合がある
例えば列を削除・置換した場合、名前の参照範囲が正しいか確認する必要がある
セルH2に式を設定し、J2にコピーしすると、合計対象範囲は、E列の金額だが、A列の名前になってしまう。その他もずれる。ずれを解消するには、INDIRECT関数を使うとできるが、デメリットの方が大きい。
INDIRECT関数を使う場合
=SUMIFS(INDIRECT("kakeibo[金額]"), INDIRECT("kakeibo[名前]"), $G2, INDIRECT("kakeibo[月]"), $I1, INDIRECT("kakeibo[区分]"), $H2)- 計算が遅くなる
(Excelは毎回文字列を評価し直すため) - 参照先のチェックが効かない
(範囲が存在しなくてもエラーにならず気づきにくい) - 数式が読みにくい
(どの列を参照しているかパッと見でわからない)
集計表は一度設定すれば終わり(基本的)なので、手修正しても問題ないと思います。むしろ、式が列名で分かりやすいので、最初の手間さえ乗り越えれば管理しやすいのがメリットでは?と。
名前の定義を利用
名前の定義(名前の管理(ネームマネージャー)」を使う方法です。
=SUMIFS(金額, 名前, $G2, 月, I$1, 区分, $H2)ここでは 金額・名前・月・区分 をそれぞれ名前の定義に設定しています。名前を使うことで式がすっきりして読みやすくなり、テーブルや列全体参照よりも直感的です。
名前の定義(名前の管理)
テーブル設定している列をそのまま参照させる方法は便利です。
金額の例:=kakeibo[金額]
OFFSET を使う方法もありますが、私は避けています。理由は、重くなったり、そもそも式の意味を追うのが大変だから。(第三者が式の意味を追いにくい)
名前の管理のメリット
- 列方向・行方向にコピーして使える
参照範囲が名前で固定されているので、コピーしてもずれにくい - 式が短くて管理しやすい
列全体参照よりもすっきりしているので、見た目も整理される - 動作が軽い(OFFSET や INDIRECT を使わない場合)
- テーブル列をそのまま参照できる
データが増えても範囲を手動で直す必要がない - 再利用しやすい
名前を定義しておけば、複数の式で同じ範囲を簡単に参照できる
名前の管理のデメリット
- 名前定義を作る手間がある
名前をひとつひとつ設定する必要があり、最初は少し面倒 - 定義する項目が多いと名前の管理の一覧画面が見づらくなる
- 定義内容を知らない人には分かりにくい
名前だけを見ると、どの範囲を参照しているかが直感的に分かりにくい場合がある - テーブル列を変更すると名前定義も見直す必要がある場合がある
例えば列を削除・置換した場合、名前の参照範囲が正しいか確認する必要がある
まとめ
SUMIFS を使った複数条件の集計では、式の書き方によって扱いやすさや管理のしやすさが変わる。
- 列全体参照
- 範囲をいちいち直さなくても使えるので一番手軽
- ただし、大量データだと計算が重くなることがある
- テーブル参照
- 列名で参照できるので式が分かりやすく、データ追加にも自動追従
- 横方向にコピーすると参照がずれることがあり、手修正が必要な場合もある
- 参照のずれを避けるためにINDIRECT関数などを組み合わせる方法もあるが、式が重くなったり可読性が落ちる
- 名前定義を利用
- 式がスッキリして直感的に分かりやすい
- 列方向・行方向のコピーにも強い
- 名前の設定が必要で、列を変更した場合は確認が必要
OFFSET を使った動的範囲は便利ですが、重くなったり式の意味が追いにくくなるので、私は避けている。
結局のところ、どの参照方法を選んでも「自分以外の誰かが使う」可能性を考えると、式の説明を残しておくことが大切だろう。あとから引き継ぐ側にとって、式の意味が分かりやすいだけで作業効率や安心感が大きく変わる。






